前言
我们很多时候想要和web站点进行交互,和他聊聊天,浏览浏览站点,找他要点东西是吧。经常听到的爬虫就是从站点上抓取自己想要的东西。本期的内容就是围绕怎么用编程的方式来向服务器发起请求,和他聊天。
其实,我们用浏览器去访问一个网站的时候。我们是通过浏览器去发送一串请数据向服务器请求,然后接受服务器的反馈。而用编程的方式,就是模拟浏览器构造数据向服务器发送请求和接受信息的过程,接下来就讲讲怎么通过Python编程来构造、请求、接收这些数据。
urllib、urllib2 、requests模块介绍
常见的与web程序进行交互的python模块为\u******rllib****、****urllib2****和****requests****,urllib和urllib2的功能相似,但也存在一定的异同,如:都是可以通过urlopen()请求一个网站,但是urllib存在urlretrieve()方法,可用于下载文件,urllib2存在Requests模块操作更简便。PS:python 3将urllib2集成到了urllib里面,即没有urllib2模块。
那requests模块是什么?是集成了以上两个模块的功能,能够很方便的与web程序进行交互。当你用了requests模块的时候,就不会想要再用urllib和urllib2了。以下主要介绍requests模块,想了解urllib和urllib2模块可自行了解。
\requests******模块****介绍****
1、安装:pip install requests
2、发送网络请求
r = requests.get(url) 获取html的主要方法
r = requests.post(url) 向html网页提交post请求的方法
r = requests.put(url) 向html网页提交put请求的方法
r = requests.delete(url) 向html提交删除请求
r = requests.head(url) 获取html头部信息的主要方法
r = requests.options(url)
3、为url传递参数
payload={'key1':'value1','key2':'value2'}
r=request.get(url,params=payload)
4、响应内容
r.text
5、二进制响应内容
r.content
6、定制请求头
headers=''
r.request.get(url,headers=headers)
7、加入cookies
cookies=''
r.request.get(url,cookies=cookies)
8、post请求加入参数
payload={'key1':'value1','key2':'value2'}
r=request.post(url,data=payload)
9、响应状态码
r.status_code ->如通过这个状态码进行目录扫描
10、返回响应头
r.headers
11、返回cookies
r.cookies
12、超时
requests.get(url,timeout=0.0001)
13、错误和异常
遇到网络问题:ConnectionError异常
无效HTTP响应:HTTPError异常
请求超时:Timeout异常
上面介绍了那么多,看起来很复杂,那么我们最基础的还是说,构造、请求、接收这些数据。用法如下:
import requests #导入Python模块
url='http://www.baidu.com' #要请求的网站
re = requests.get(url) #请求网站
result = re.text #响应的内容
print(result) #打印响应结果

然后再用我们上期内容讲到的正则匹配就可以抓取我们想要的内容。
那有朋友又要说了,我抓到的怎么是<!DOCTYPE html>什么什么的东西呢!那是因为我们看到的响应内容是站点的源码,你可以用右键查看源码的方式,查看源码的内容。

爬虫
按照设定的规则,自动的去爬取万维网信息的程序或脚本。
优点:(批量、自动化)=(省时、省力)
安全应用角度:用于目录扫描、搜索测试页面、搜索管理员登录界面、开发web的漏洞扫描。
实战:利用python开发一个爬虫

针对这个需求,我们写了个爬虫,先爬取页面的信息,再通过上一篇文章学习的正则匹配去匹配里面的内容。
效果如下:
第一步,先尝试爬取页面的信息,发现我们爬取的中文都是乱码的

我们加入r.encoding ='utf-8' 调整编码格式,就可以得到正常的情况

第二步,我们先尝试爬取文章名称,我们利用查看源码的功能或者我们爬下来的源码去分析我们要提取的内容前后的特征,可以看到我们要提取的今日推荐文章名字的前面都是title=”
后面是" class="lb_1 chao">

那么我们可以书写正则匹配:r'title="(.*?)" class="lb_1 chao">'
尝试进行匹配,可以看到,我们爬取到了文章名称,验证一下发现和截图里面的内容是一致的

第三步:用同样的方法去匹配文章对应的链接,简单的调整一下,我们就得到如下的结果

将链接拿出来测试一下,发现无误,爬取成功,目标达成(每天跑一下,就可以看到该站点的每日推荐信息)。

*公众号回复“和web聊天”获取爬虫源码。*
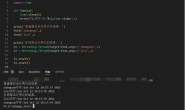
全部代码如下:(#号注释的内容,除了第一条,其他的均为开发过程中的测试语句,可以删除。删除之后你会发现,我们实现这个功能所需代码量很少。)
# encoding:utf-8
import requests
import re
url = 'https://www.xuexila.com/'
r = requests.get(url)
r.encoding ='utf-8'
# print(r.text)
pattern = r'title="(.*?)" class="lb_1 chao">'
title = re.findall(pattern,r.text)
# print(title)
# for i in title:
# print(i)
pattern2 = r''
links = re.findall(pattern2,r.text)
# print(links)
# for link in links:
# print(link)
for i in range(0,len(links)):
print(title[i]+' '+links[i])